The FARI Conference returns on 17 and 18 November in Brussels, find out more.
An Initiative of
Supported by

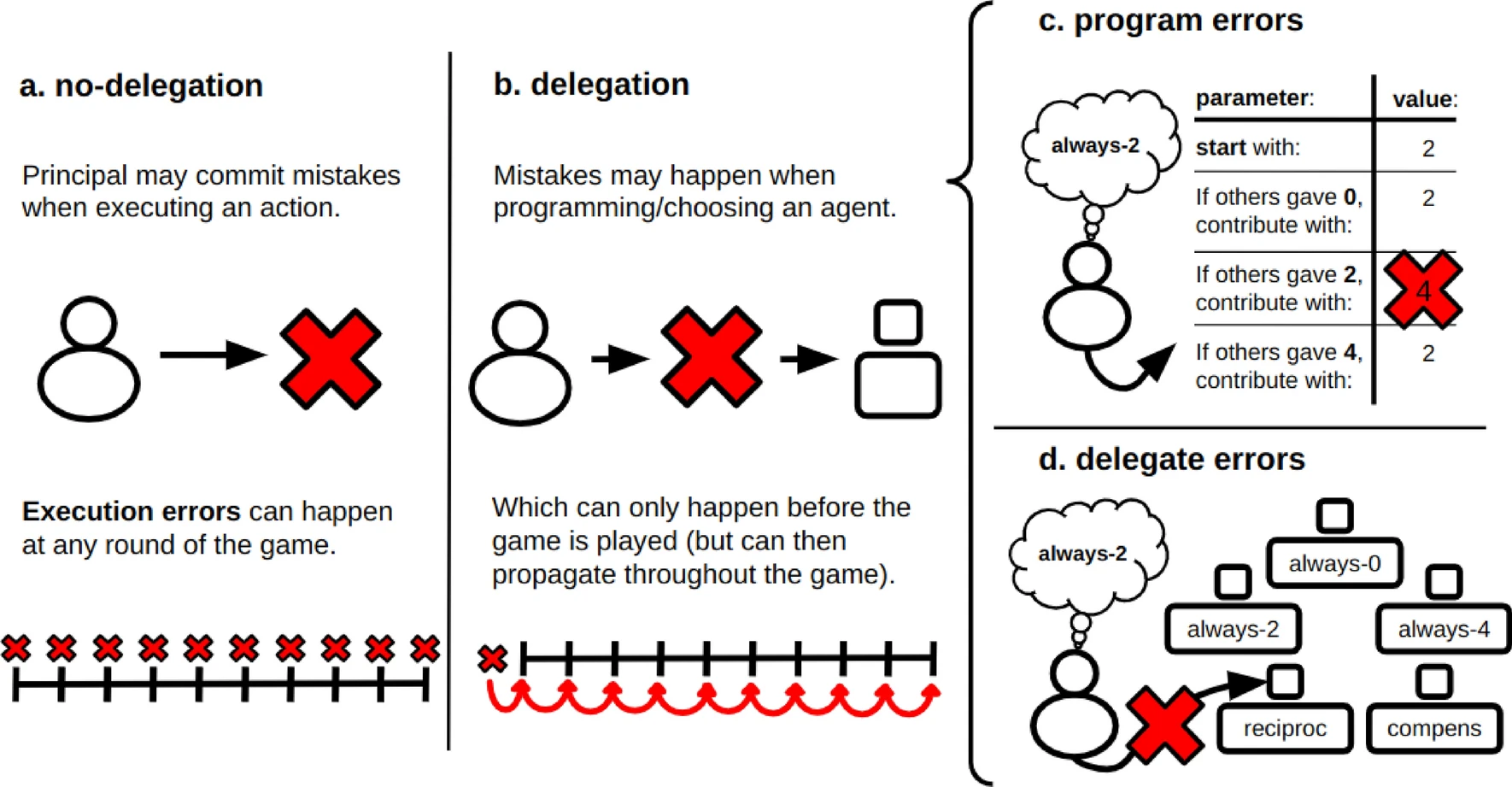
Committing to the wrong artificial delegate in a collective-risk dilemma is better than directly committing mistakes
AUG 2024
Abstract
While autonomous artificial agents are assumed to perfectly execute the strategies they are programmed with, humans who design them may make mistakes. These mistakes may lead to a misalignment between the humans’ intended goals and their agents’ observed behavior, a problem of value alignment. Such an alignment problem may have particularly strong consequences when these autonomous systems are used in social contexts that involve some form of collective risk. By means of an evolutionary game theoretical model, we investigate whether errors in the configuration of artificial agents change the outcome of a collective-risk dilemma, in comparison to a scenario with no delegation. Delegation is here distinguished from no-delegation simply by the moment at which a mistake occurs: either when programming/choosing the agent (in case of delegation) or when executing the actions at each round of the game (in case of no-delegation). We find that, while errors decrease success rate, it is better to delegate and commit to a somewhat flawed strategy, perfectly executed by an autonomous agent, than to commit execution errors directly. Our model also shows that in the long-term, delegation strategies should be favored over no-delegation, if given the choice.
Authors: Inês Terrucha, Elias Fernández Domingos, Pieter Simoens & Tom Lenaerts

Contributors

Share
Other publications

Report
Automating the Achievement of SDGs: Robotics Enabling & Inhibiting the Accomplishment of the SDGs
Date
MAY 2022
Researchers
Date
AUG 2024
Researchers

Report
Legal Requirements for Automated Coordination Mechanisms for the Sharing of Energy Through Proxies
Date
FEB 2025
Researchers

Journal Article
Delegation to artificial agents fosters prosocial behaviors in the collective risk dilemma
Date
MAY 2022
Researchers

Date
DEC 2024
Researchers